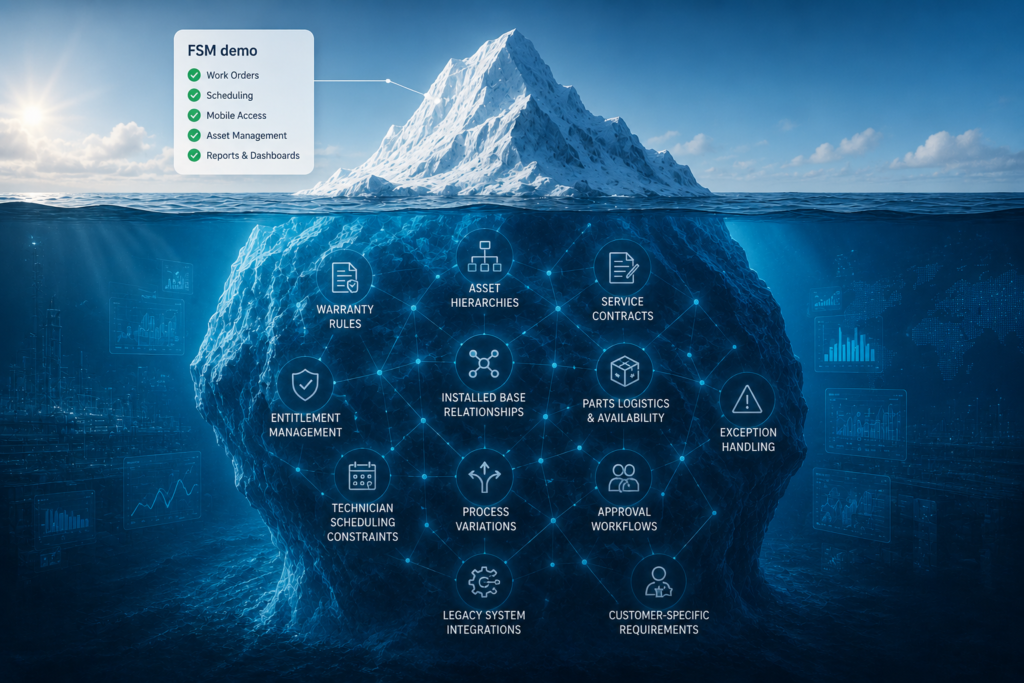
Most FSM rollouts don’t fail because the software is wrong. They fail because of an FSM capability gap that nobody tested for before signing, and the story below shows exactly how that plays out.
A manufacturer I worked alongside rolled out a new asset management capability inside their field service platform. On paper, the tool had everything they needed. Nothing in the evaluation raised any major concerns. The business case was approved, the timeline was set, and implementation began.
Midway through, the team hit a wall. The specific capability they were counting on, the one that justified a chunk of the business case, existed in the product, but not at the level of maturity their process actually demanded. It could handle a simple version of their workflow. It couldn’t handle the real one, with all its edge cases and exceptions.
The team had to go back to the vendor, and before any real configuration work could start, they had to pay for additional consulting time just to get the vendor to understand what the use case actually required. Six months later, they had something workable. Full capability took further iterations beyond that. In the meantime, the business ran on workarounds that were worse than what they’d had before the project started, because the old process had at least been stable, and the half-built new one wasn’t.
This kind of gap shows up often in installed base management specifically, where asset complexity tends to outpace what a standard FSM configuration assumes.
Nobody on that team was incompetent. The vendor wasn’t dishonest. The demo wasn’t even wrong. The evaluation had focused on whether the platform could perform the process, not whether it could perform the process at the level of complexity the business actually required.
That gap between “the product can do this” and “the product can do this for us” rarely appears during vendor demos. It appears during implementation, when changing course is slow, expensive, and politically difficult.
The Real Problem: Capability Fit, Not Feature Fit
Most conversations around FSM implementations focus on the upside such as predictive maintenance, uptime gains, cost reduction, the advanced capabilities managers are buying the tool for in the first place. Change management gets mentioned, usually last, almost as a footnote. But there’s something even further upstream that rarely gets named at all: the organization never rigorously mapped its own process complexity against what the tool could actually deliver, natively, before signing.
Every organization configures differently. The same FSM platform that fits one manufacturer’s warranty workflow perfectly might be structurally wrong for another’s, even in the same industry. A demo environment is built to show capability in its best light, not to stress-test it against your edge cases, your exceptions, your parts logic, your multi-entity complexity. That validation work is almost always skipped, deferred, or done superficially, and it has to happen somewhere. If it doesn’t happen before the contract is signed, it happens during implementation, under deadline pressure, by whoever’s in the room.
There’s a reason this gap is so easy to miss. Capability claims in a sales cycle are almost always phrased as binary “yes, the platform handles warranty claims,” “yes, it supports multi-entity parts pricing.” But capability isn’t binary. It has depth. A platform can genuinely do something, and still not do it at the depth your operation needs once real volume, real exceptions, and real edge cases get layered on top. That distinction, does it exist versus is it deep enough, is exactly where the FSM capability gap actually originates, long before anyone notices it.
Most of what passes for FSM implementation best practices today still treats this as a configuration problem, not a fit problem. If you’re earlier in the buying process, this is exactly the kind of depth-testing a structured vendor evaluation is built to catch before a contract gets signed.

Pre-Implementation: Where Success or Failure Is Decided
Most implementation problems are embedded in the project before the contract is signed. This is the phase where organizations decide whether they are buying a platform that fits their operation or one that merely appears to fit.
- Demo-driven buying: A capability shown working smoothly in a controlled demo is not the same as a capability validated against your actual process. Sales environments are built to avoid friction, not to surface it.
- No structured capability audit. Every requirement in an FSM rollout falls into one of three buckets, and most organizations never separate them: Native fit, Configurable, and Not yet mature.
| Category | What It Means | Who Should Validate It | Risk If Skipped |
|---|---|---|---|
| Native Fit | Works out of the box, proven against your actual process | Business + IT jointly | Low, but only if genuinely tested, not assumed |
| Configurable | Achievable with real configuration effort | IT/SI with business sign-off | Medium. Scope and timeline creep |
| Not-Yet-Mature | Exists on paper, lacks depth for your complexity | Business stakeholders with edge-case knowledge | High. Surfaces mid-build, most expensive to fix |
Without this audit, all three get treated as “yes, the tool does that” at the proposal stage. The difference only becomes visible once someone tries to actually build it.
- Business stakeholders left out of the room: Process owners, frontline supervisors, parts and warranty teams, the people who know where the edge cases live, are often informed of the new tool rather than consulted on it. Discovery gets handed to IT and the systems integrator, who can map screens but can’t always anticipate operational exceptions.
- Edge cases get discovered, not designed for: Most process discovery sessions map the happy path, the workflow that covers 80% of cases cleanly. The remaining 20% (multi-site transfers, exception approvals, non-standard warranty claims) often doesn’t get surfaced until someone hits it live, because nobody asked the frontline supervisors and warranty desk what actually breaks the standard flow on a bad week.
- Procurement timelines don’t budget for capability testing. Even when teams want to validate depth, not just existence, the contracting timeline rarely has room for it. Sandbox testing against real edge cases takes weeks the procurement cycle hasn’t set aside, so the validation either gets compressed into a token exercise or skipped in favor of moving the deal forward. It’s the same upstream mistake behind why planning has to come before the dispatch console in scheduling, the tool gets blamed for a gap that was actually a process question nobody answered first.
During Implementation: Where the Gap Demands a Decision
Whatever wasn’t caught before signing forces itself onto the table now, and someone has to decide what happens next.
The workaround decision gets made by default. When a capability turns out to be configurable-with-effort or not-yet-mature, someone has to choose: invest in custom build, push the vendor for a roadmap fix, or bend the process to fit what the tool can already do. That third option, bending the process, is usually the path of least resistance under a deadline. It’s also the one the business resists hardest, because it means changing how people actually work to suit the software, not the other way around.
No one owns the call. That decision rarely gets made cleanly. Without one person accountable end-to-end, it gets made by committee, by whoever’s loudest in the room, or by default when nobody decides at all and the deadline ends up deciding for them.
The vendor relationship shifts in character. Once a capability gap surfaces, what started as “configure this for us” becomes “build this for us,” and that change in scope rarely comes with a corresponding change in the timeline expectations leadership is still anchored to.
The real cost goes untracked. The man-hours spent getting a vendor to understand a custom requirement, the extended timeline, the parallel cost of running workarounds in the meantime, these tend to get absorbed quietly rather than tracked as one clear line item. They show up scattered across budget overruns, delayed KPI improvements, and “implementation support” invoices, which makes the true cost of the original capability-fit miss hard to see even after the fact.
Training becomes an afterthought. Through all of this, training tends to get treated as a go-live checklist item rather than the ongoing capability transfer it actually needs to be, helping technicians and supervisors understand not just how to click through the new tool, but why the process changed in the first place.
Post-Implementation: Where the Cost Surfaces
By the time the system is live, the unresolved gap has usually hardened into something harder to fix.
Workarounds become shadow processes. The bent process or the manual patch doesn’t go away after go-live, it becomes the new normal, running quietly alongside the official system.
Adoption metrics can look healthy on paper while actual engagement stays shallow, with technicians doing the minimum required and quietly routing real work elsewhere. The easiest story to tell at this point is that the tool failed, and it’s also the wrong one. The tool did what it was capable of doing, the failure was an unvalidated capability-fit decision made months earlier, under a deadline, by whoever happened to be in the room.
That disappointment often reshapes how the next vendor gets evaluated, but usually for the wrong reasons: the instinct is to distrust the next vendor’s claims wholesale rather than fix the evaluation process itself, which doesn’t make the next implementation any safer, it just slows the decision down without closing the actual gap. Meanwhile, the workaround that was meant to be temporary rarely disappears. Years later, new hires inherit a manual process step with no one left who remembers it was ever supposed to be short-term, it’s no longer seen as a gap, just “how we do it here,” quietly adding friction to every workflow downstream of it.
A Pre-Signing Capability Audit Checklist
Before configuration starts, ideally before the contract is signed, these are the questions that catch an FSM capability gap while it’s still cheap to fix.
None of these questions are hard to ask. They’re just easy to skip when a demo looked good and a timeline is already set, which is exactly where most FSM implementation best practices fall short in practice. The organizations that skip them don’t find out until they’re six months into a fix they didn’t budget for.
Evaluating an FSM platform? Check out the FSM Vendor Assessment Framework here.
Share your experience via the contact form. Practitioner inputs shape the content on this site.